Project Cheetah - Faster, Leaner Pipeline That Can Keep Up With Demand
| This is a guest post by Sam Van Oort, Software Engineer at CloudBees, and contributor to the Jenkins project, and maintainer of the Pipeline Plugins. |
Since it launched, Pipeline has had a bit of a Dr. Jekyll and Mr. Hyde performance problem. In certain circumstances, Pipeline can turn from a mild-mannered CI/CD assistant into a monster. It will happily eat storage read/write capacity like popcorn without caring about the other concerns of our friendly butler. When combined with other additional factors, this can result in real-world stability problems. For example, combining slow storage with a spike in running Pipelines has brought down production Jenkins at more than one organization. Similarly, users see issues if a busy controller gets hit with an extra source of stress; past culprits have been heavy automated (ab)use of Jenkins APIs, now-solved user lookup bugs, backup jobs, and plugins run crazy that load excessive numbers of builds. Symptoms ranged from visible slowdowns in the UI to unresponsive jobs and "hung" controllers.
Now I’m not saying this to scare people or to criticize the technology we’ve built. Implementing Pipeline scalability best practices coupled with SSD storage keeps Jenkins in a happy place. We just need context on the weaknesses to see why it’s important to address them.
Introducing "Project Cheetah"
Today we’re announcing the first major results of "Project Cheetah", our long-running effort to address these challenges and improve Pipeline scalability. More broadly, Cheetah aims to help in 3 places:
-
Small-scale containers: Pipeline needs to run leanly in resource-constrained containers, to enable easy scale-out without consuming excessive resources on shared container hosts.
-
Enterprise systems: Pipeline needs to effectively serve high-scale Jenkins instances that are central to many large companies.
-
General case: run Pipelines a bit more quickly on average, and allow users to get much-stronger performance in worst-case scenarios.
These changes are implemented across many of the Pipeline plugins.
Yes, but what does it DO?
Project Cheetah offers several things, but the most important is Durability Settings for all Pipelines, and especially the Performance-Optimized setting. This setting avoids several potentially unexpected performance "surprises" that may strike users. In the general case, it greatly reduces the disk IO needs for Pipeline. How much? Below is a graph of storage utilization with legacy Pipeline versions (think early 2017) and with the latest version using the Performance-Optimized mode. These are tested on an AWS instance backed by an EBS volume provisioned with 300 IOPs.
Before and After:
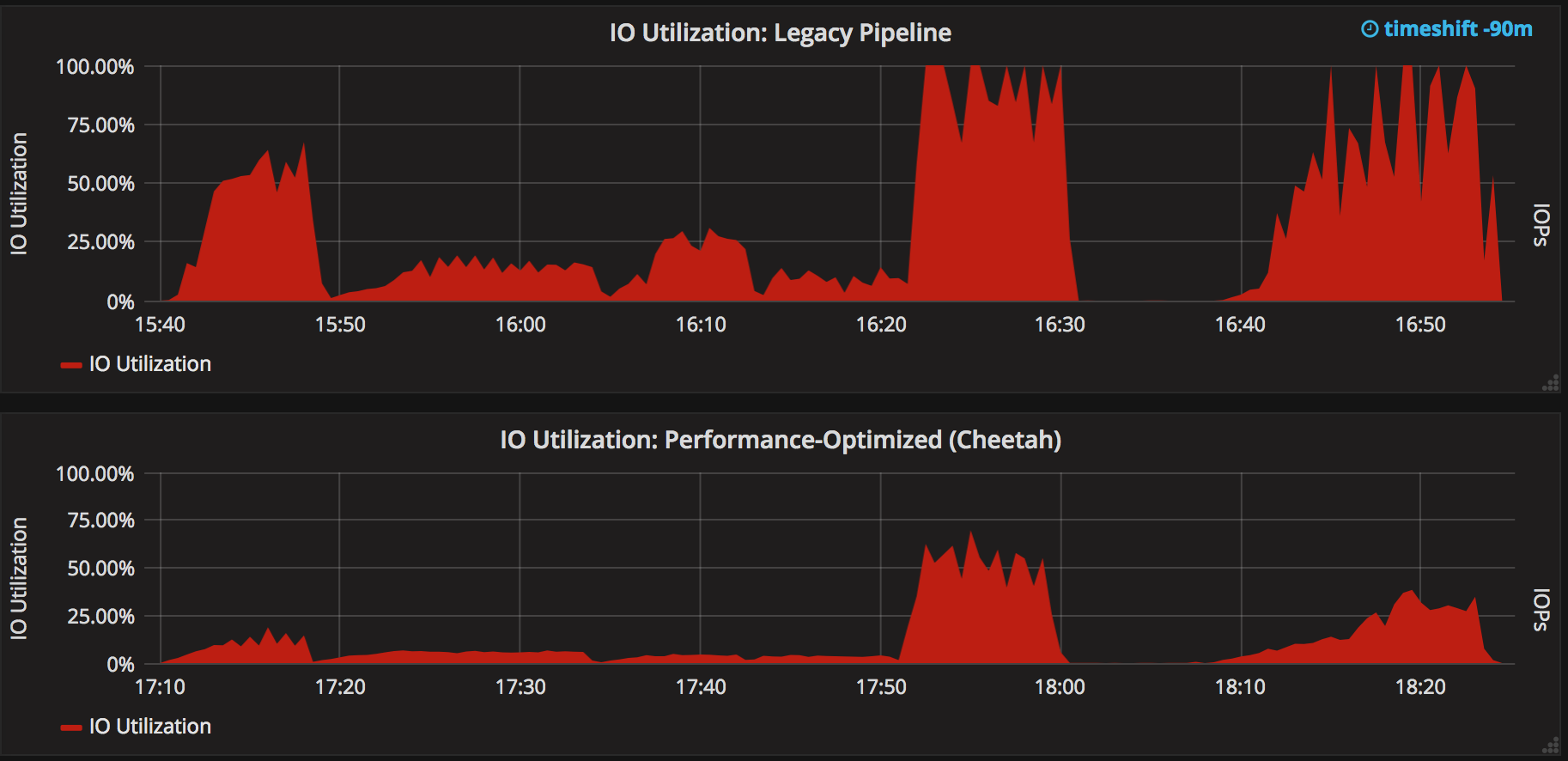
As you can see, storage utilization goes down by a lot. While the exact number will vary, across the benchmark testcases this results in Pipeline throughput of 2x to 6x the previous before becoming IO-bound. This also increases stability of Jenkins controllers because they will tolerate unexpected load.
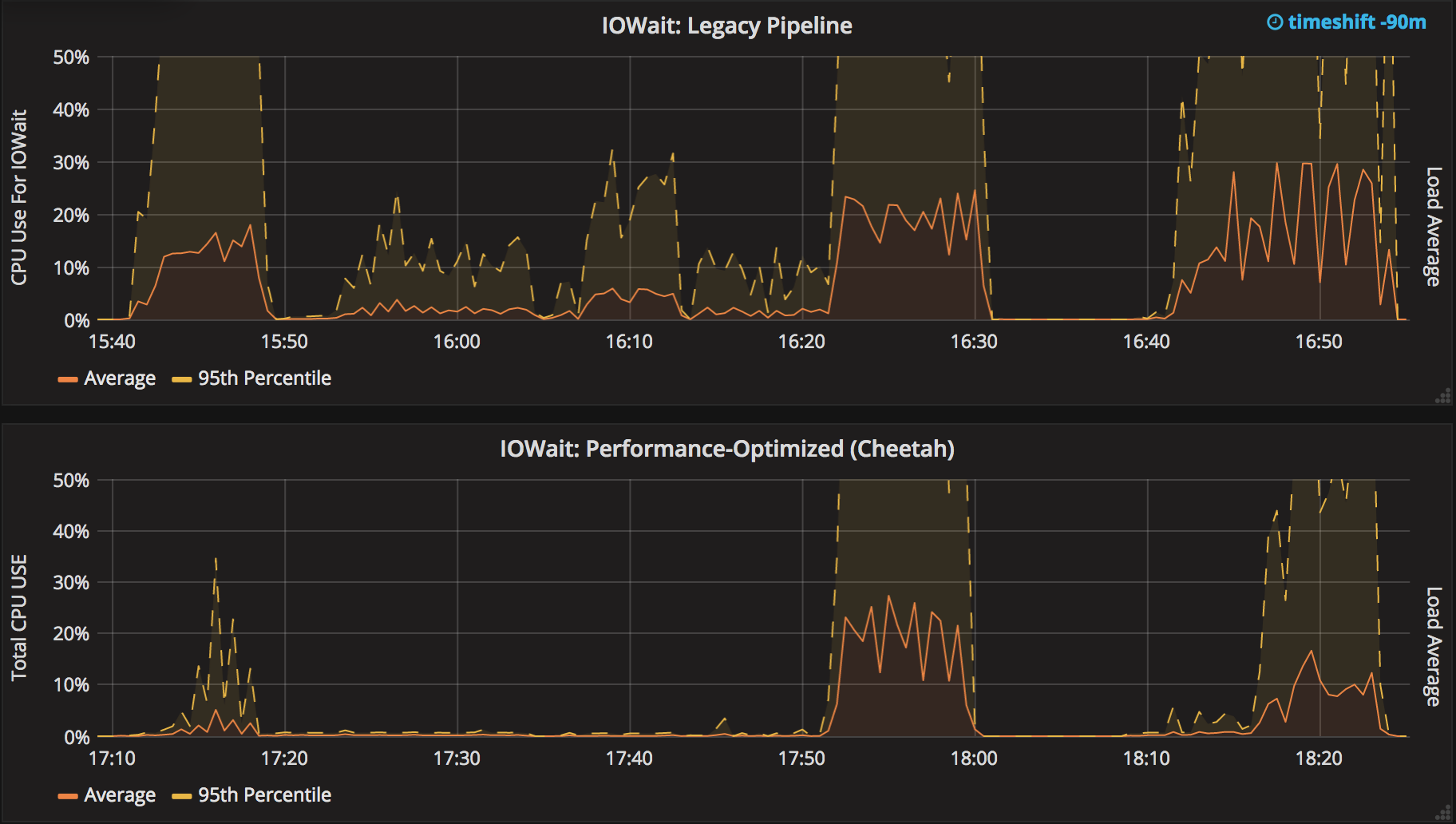
This comes with a major drop in CPU IOWait as well:
And of course the rate at which data is written to disk and number of writes/s is also reduced:
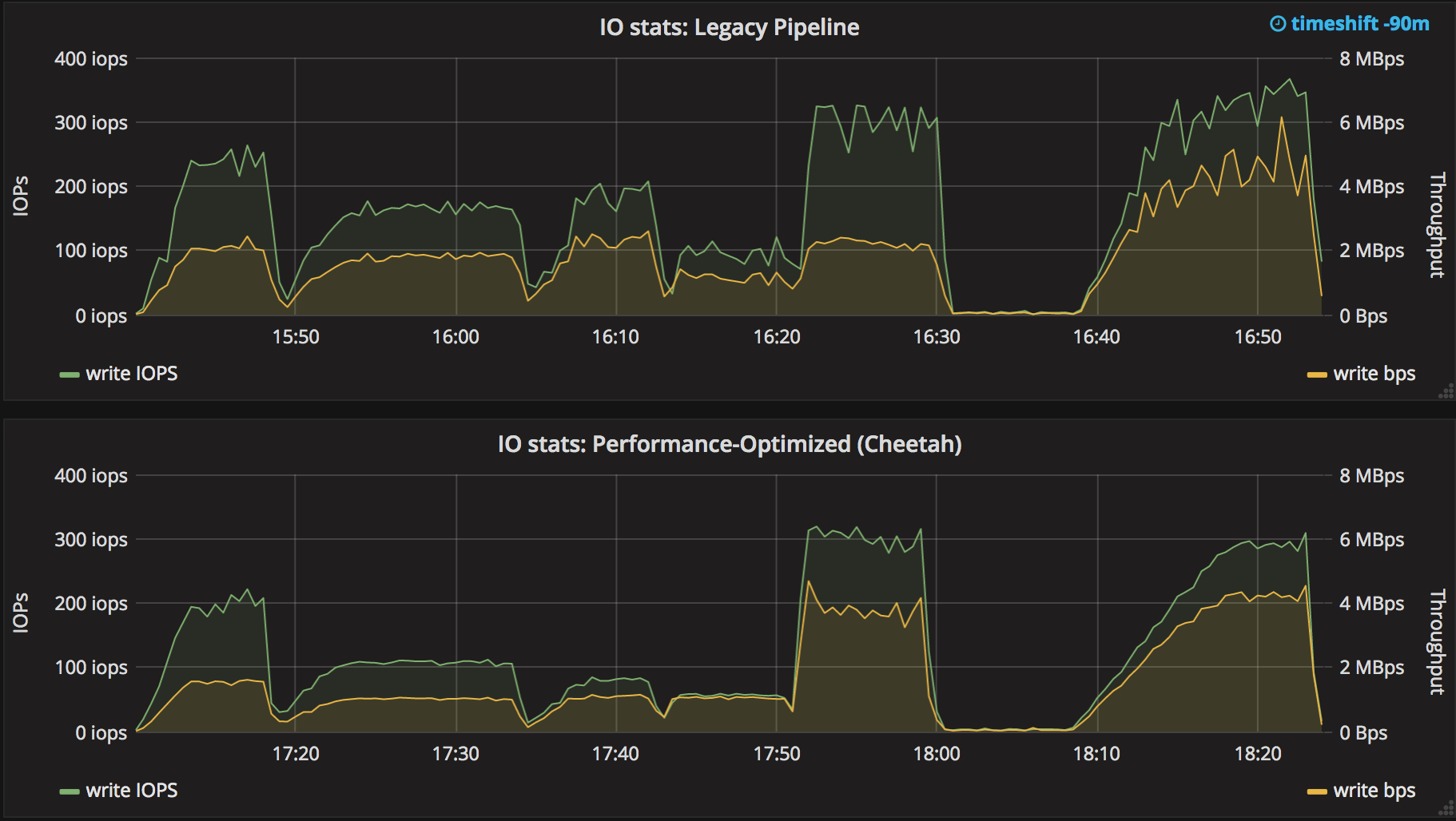
For enterprise users, timing stats often show 10-20% of normal builds is serializing the Program and writing the record of steps run ("FlowNodes") - the performance optimized durability setting will cut this to almost nothing (for standard pipelines, 1/100 or less) - so builds will complete faster, especially complex ones.
Please see the Pipeline Scalability documentation for deeper information on the new Durability Settings, how to use them, and which plugin versions are required to gain these features.
Also, users may see a reduction in hung Pipelines because new test utilities made it possible to identify and correct a variety of bugs.
How Do I Set Speed/Durability Settings?
There are 3 ways to configure the durability setting:
1. Globally, you can choose a global default durability setting:
Under "Manage Jenkins" > "Configure System", labelled "Pipeline Speed/Durability Settings". You can override these with the more specific settings below.

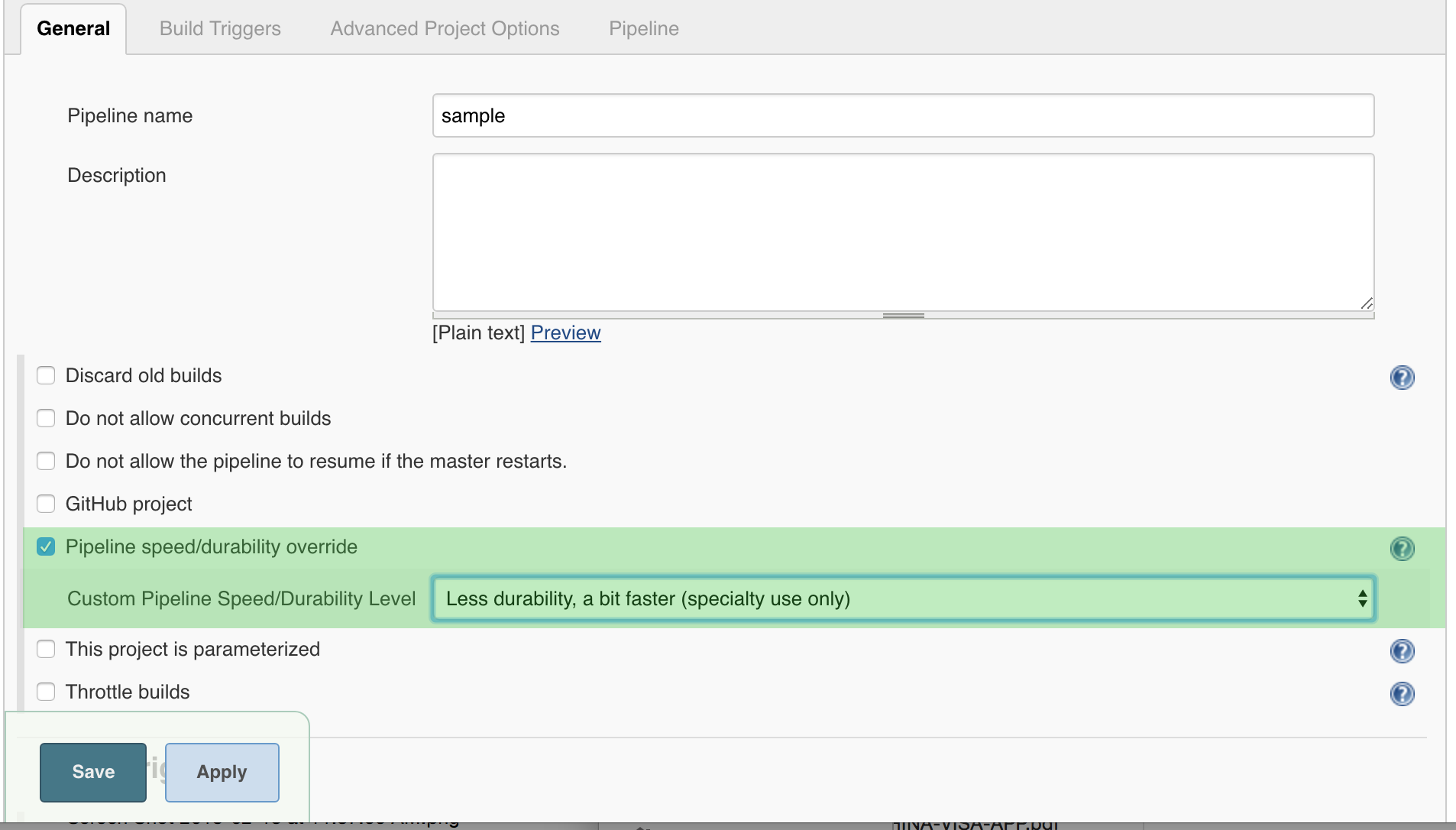
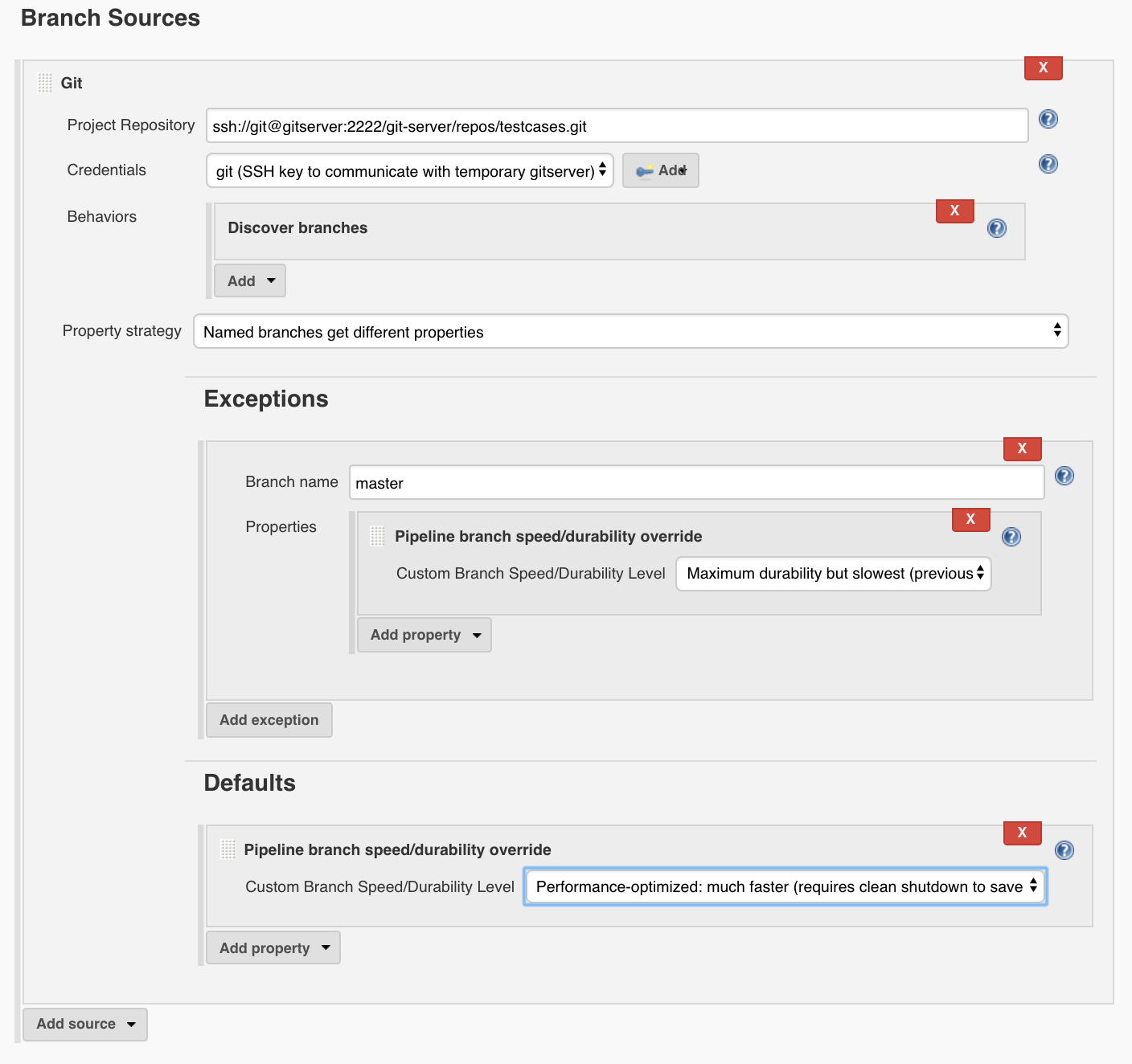
2. Each Pipeline can get a custom Durability Setting:
This is one of the job properties located at the top of the job configuration, labelled "Custom Pipeline Speed/Durability Level." This overrides the global setting. Or, use a "properties" step - the setting will apply to the NEXT run after the step is executed (same result).
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
options {
durabilityHint('PERFORMANCE_OPTIMIZED')
}
}3. Multibranch Projects can use a new BranchProperty to customize the Durability Setting.
Under the SCM you can configure a custom Branch Property Strategy and add a property for Custom Pipeline Speed/Durability Level. This overrides the global Durability Setting and will apply to each branch at the next run. You can also use a "properties" step to override the setting, but remember that you may have to run the step again to undo this.
Durability settings will take effect with the next applicable Pipeline run, not immediately. The setting will be displayed in the log.

There is a slight durability trade-off for using the Performance-Optimized mode — the appropriate section of the Pipeline Scalability documentation has the specifics. For most uses we do not expect this to be important, but there are a few specific cases where users may wish to use a slower/higher-durability setting. The Best Practices are documented.
We recommend using Performance-Optimized by default, but because it does represent a slight behavioral change the initial "Cheetah" plugin releases defaults to maintain previous behavior. We expect to switch this default in the future with appropriate notice once people have a chance to get used to the new settings.
Will Performance-Optimized Mode Help Me?
-
Yes, if your Jenkins instance uses NFS, magnetic storage, runs many Pipelines at once, or shows high iowait (above 5%)
-
Yes, if you are running Pipelines with many steps (more than several hundred).
-
Yes, if your Pipeline stores large files or complex data to variables in the script, keeps that variable in scope for future use, and then runs steps. This sounds oddly specific but happens more than you’d expect.
-
For example:
readFilestep with a large XML/JSON file, or using configuration information from parsing such a file with One of the Utility Steps. -
Another common pattern is a "summary" object containing data from many branches (logs, results, or statistics). Often this is visible because you’ll be adding to it often via an add/append or
Map.put()operations. -
Large arrays of data or Maps of configuration information are another common example of this situation.
-
-
No, if your Pipelines spend almost all their time waiting for a few shell/batch steps to finish. This ISN’T a magic "go fast" button for everything!
-
No, if Pipelines are writing massive amounts of data to logs (logging is unchanged).
-
No, if you are not using Pipelines, or your system is loaded down by other factors.
-
No, if you don’t enable higher-performance modes for pipelines. See above for how!
Other Goodies
-
Users can now set an optional job property so that individual Pipelines fail cleanly rather than resuming upon restarting the controller. This is useful for niche cases where some Pipelines are considered disposable and users would value a clean restart over Pipeline durability.
-
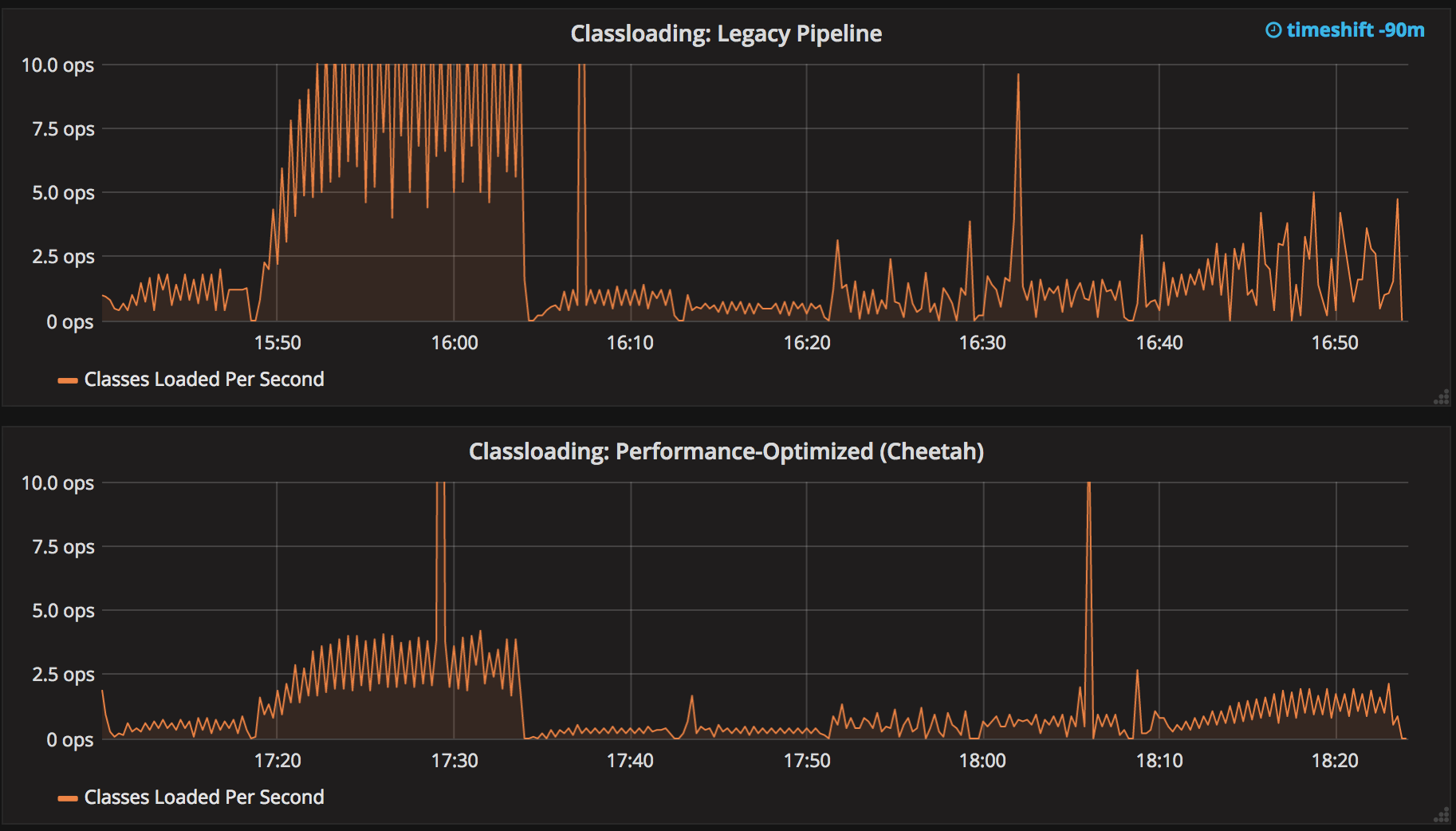
We’ve reduced classloading and reflection quite significantly, which improves scaling and reduces CPU use:
-
Script Security (as of version 1.41) has gotten optimizations to reduce the performance overhead of Sandbox mode and eliminate lock contention so Pipeline multithreads better.
-
Pipeline Step data uses up less space on disk (regardless of the durability setting) - this should be 30% smaller. Assume it’s a few MB per 1000 steps - but for every build after the change.
-
Even in the low-performance/high-durability modes, some redundant writes have been removed, which decreases the number of writes by 10-20%.
How Did You Do It?
That’s probably material for another blog post or Jenkins World talk.
The short answer is: first we built a tool to simulate a full production environment and provide detailed metrics collection at scale. Then we profiled Jenkins to identify bottlenecks and attacked them. Rinse and repeat.
What Next?
The next big change, which I’m calling Cheetah Part 2 is to address Pipeline’s logging. For every Step run, Pipeline writes one or more small log files. These log files are then copied into the build log content, but are retained to make it possible to easily fetch logs for each step.
This copying process means every log line is written twice, greatly reducing performance, and writing to many small files is orders of magnitude slower than appending to one big log file.
We’re going to remove this duplication and data fragmentation and use a more efficient mechanism to find per-step logs. This should further improve the ability to run Pipelines on NFS mounts and hard-drive-backed storage, and should significantly improve performance at scale.
Besides this, there’s a variety of different tactical improvements to improve scaling behavior and reduce resource needs.
The Project Cheetah work doesn’t free users to completely ignore Pipeline scaling best practices and previous suggestions. Nor does it eliminate the need for efficient GC settings. But this and other enhancements from the last year can significantly improve the storage situation for most users and reduce the penalties for worst-case behaviors. When you add all the pieces together, the result is a faster, leaner, more reliable Pipeline experience.

|
Sam Van Oort
This author has no biography defined. See social media links referenced below. |